并发无外乎进程,线程,协程三种方式。 Python 由于GIL锁的存在,多线程有些鸡雏,只能跑在一个核上。多进程各种语言差不多,创建开销比较大。
协程并不是操作系统内核提供的,它是用户态下实现的。协程主要用在网络上。参考许式伟的文档:大部分你看到的协程(纤程)库只是一个半吊子。它们都只实现了协程的创建和执行权的切换,缺了非常多的内容。包括:
- 协程的调度;
- 协程的同步、互斥与通讯;
- 协程的系统调用包装,尤其是网络 IO 请求的包装。
python3 的协程主要是 asyncio + aiohttp 实现,其中 aiphttp还存在不少坑。如果是 python2 可以用 gevent 或者 eventlet 之类的库。
业务类型
在考虑使用哪种并发模型前,我们需要知道我们的业务场景是什么样的,如果是计算密集的,那多进程的方式肯定速度比较快,如果是I/O密集的,那多线程或者是协程可能比较快。
并发模型
常见的并发模型主要用有以下几种:
- 协程
- 进程 + 队列
- 进程池
- 线程 + 队列
- 线程池
池化
线程/进程池的思想是提前创建好线程/进程,然后分配任务,减少了线程/进程的创建和销毁时间。
实例说明
这里我们以请求网站为例,来说说使用哪种模型比较好。假设我们有一批url,需要提取每个url的内容。很明显这是一个I/O密集的场景,CPU使用并不高。我们先来试试线程池的性能。
使用线程池一个需要考虑的地方是线程池的大小设置为多少比较合理。设置小了性能得不到充分发挥,设置大了,会带来很多上下文切换,也会影响性能。这里有一篇文章可以参考下: 如何合理地估算线程池大小
大致算法如下:
1 | 最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目 |
先来看看这个模型有哪些阶段的耗时:
- 线程池的创建时间
- 组织并发送http报文时间: 时间很短
- I/O等待时间: 以百度为例,请求一次大概 0.6s, 很多url 的时间都要高于这个时间;
- 线程上下文切换时间: 线程的切换是由操作系统完成的,这个我们无法干预;
但是前面也提到了,python的多线程只会跑在一个核上,所以这个公式并不是很适合python。而且线程等待时间和线程CPU时间也不是很好统计。我们先自己测试下,看看结果。
测试环境
- CPU: 2.2GHZ, 8核
- Memory: 16GB
- Python: 3.7
- 参数设置: timeout: 5s
测试结果
先用 http://www.baidu.com 测试下:
| 线程池大小 | 时间(url=1) | 时间(url=100) | 时间(url=1k) | 时间(url=2k) | 时间(url=1w) |
|---|---|---|---|---|---|
| 10 | 0.0609200000763 | 0.758232116699 | 6.39800596237 | 17.6599781513 | 66.2937660217 |
| 20 | 0.0540590286255 | 0.528448104858 | 8.01393008232 | 9.23072099686 | 47.8504650593 |
| 50 | 0.0577878952026 | 0.560682058334 | 5.14659905434 | 11.6546461582 | 57.1829109192 |
| 100 | 0.0589618682861 | 0.531494140625 | 5.29938697815 | 14.6375288963 | 53.1387097836 |
| 200 | 0.0584230422974 | 0.51756310463 | 5.5145201683 | 12.4125711918 | 58.5326759815 |
| 500 | 0.0581228733063 | 0.514012098312 | 5.38542103767 | 11.0087881088 | 57.4718120098 |
http://www.baidu.com 单次访问的时间大概在 60ms 左右,对于外网,这算比较短的。
url=1:python 的线程池是在需要的时候才创建线程,而不是一开始就把所有线程创建好,所以这个时间和不用线程池时间是差不多的;url=100: 较前一列数量翻了100倍,但是时间只增加了10倍。这一列的数据可以看出,线程池的创建时间相对于I/O可以忽略不记;url=1k: 较前一列数量翻了10倍,时间增加了10倍;url=2k: 较前一列数量翻了2倍,时间增加了2倍;url=1w: 较前一列数量翻了5倍,时间增加了5倍;
从上面的数据库,当 url 访问比较快时(50ms左右),线程池大小在10-20左右比较合理。你可能好奇,线程池设置为 500, 当数量足够多的时候,是否真的能用满线程池,这个很好验证,开两个shell终端,一个运行脚本,另一个通过 ps -T <pid> 查看线程数量。实际结果是可以跑满线程池的。
再换个慢点的 https://github.com/试试:
| 线程池大小 | 时间(url=1) | 时间(url=100) | 时间(url=1k) | 时间(url=2k) | 时间(url=1w) |
|---|---|---|---|---|---|
| 10 | 2.51842594147 | 41.9331200123 | 382.749531984 | 741.501072884 | |
| 20 | 2.7753970623 | 20.896089077 | 191.076680899 | 357.12337184 | |
| 50 | 1.81620693207 | 15.8236629963 | 69.2691161633 | 122.876123905 | |
| 100 | 2.12484884262 | 10.5488679409 | 38.2335569859 | 60.0130498409 | |
| 200 | 2.54932188988 | 13.314850091 | 21.380851984 | 31.7573349476 | |
| 500 | 2.96766090393 | 11.7406990528 | 17.1419959068 | 26.198912859 |
看出来了吗,当线程池的数量增加,时间明显的减少了。理想情况下,忽略线程调度和切换的时间,大致满足如下公式:
1 | 总耗时 = url数量/线程池大小 * 单个 url 耗时 |
再换一批不同的 url 测试下:
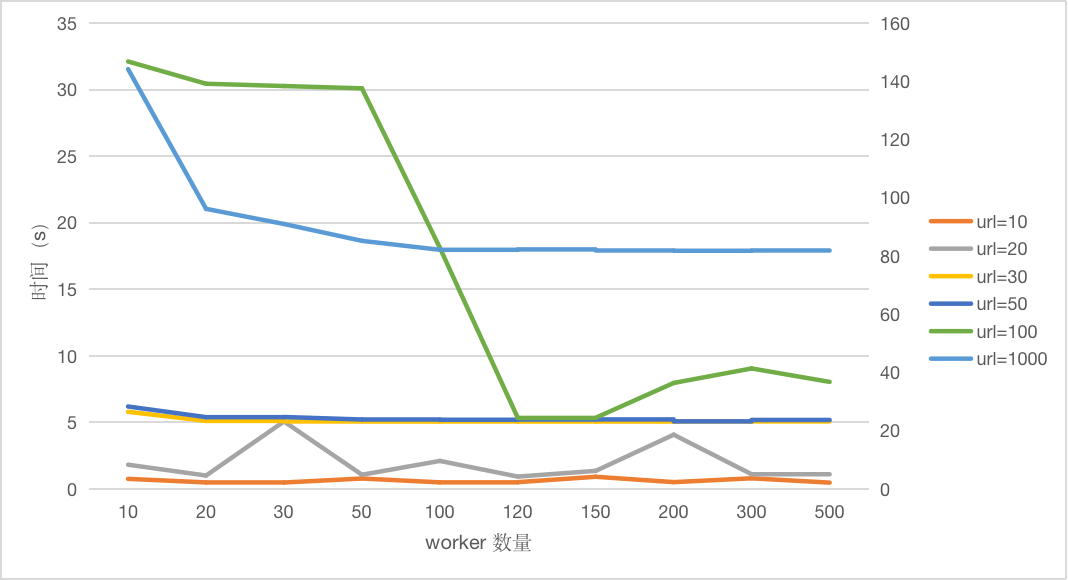
- 先看看 url=1000 的这条线(以右边坐标轴为准),可以发现随着 worker 数量增加,耗时逐渐减少,在worker=100 处趋于平稳;
- url=10 时,耗时基本都在 0.7s左右。这个时候线程池可以放下所有的url, 所以耗时跟 worker数量无关,基本很快就完成了;
- 再看看url=100这条线,worker 数量在 120-500 的时候,基本都维持在 5s左右。
因为是网络测试,所以有一定随机性,网络带宽和稳定性,数据样本对测试结果影响比较大!
结论
- 线程池的大小在达到一定值时趋于饱和,具体跟样本有关(ThreadPoolExecutor 的默认大小是 CPU核心 * 5);
- 当url数量小于worker数量时,耗时基本相同;
- 并不是线程越多越好,创建线程需要消耗内存,带来上下文切换,而且一个系统能创建的线程数量也是有限制的,可以使用
ulimit -a查看。